
The internet is crucial to the advancement of human understanding. At the beginning of 2021, there were 4.66 billion active internet users, or 59.5 percent of the world’s population.
Web browsing and data retrieval are essential aspects of our life, yet doing it manually requires a lot of time and effort.
This issue is resolved by the BOTs, which automate the majority of our tasks and increase productivity. As not all BOTs are created equal, harmful BOTs are blocked by website security. As a result, despite their many advantages, they can be contentious.
Here, we’ll concentrate on techniques that can be applied to get around issues and make data extraction simple without being obstructed.
Good BOTs vsBad BOTs
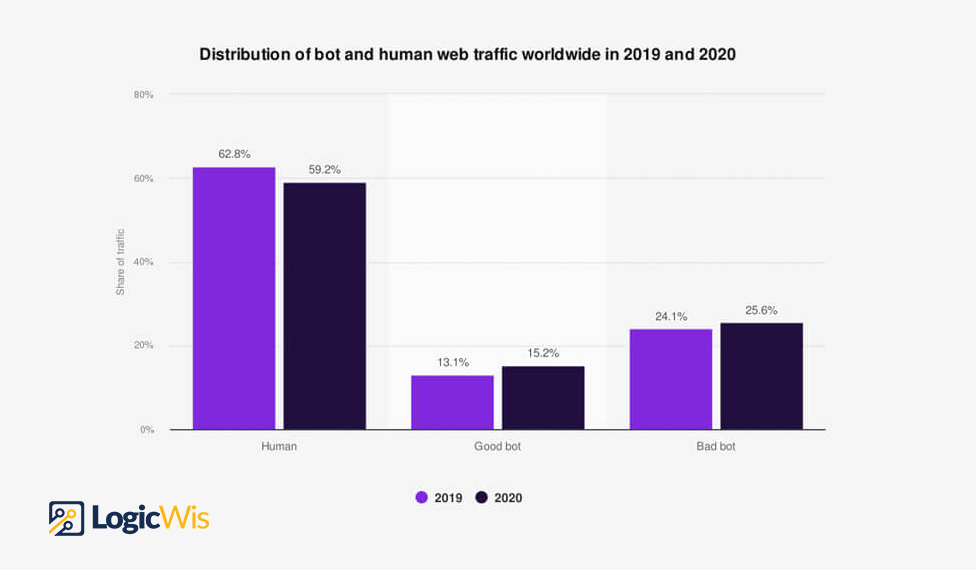
BOTs already account for a considerable amount of internet traffic.
Good BOTs refrain from carrying out helpful tasks that do not detract from the user experience. Examples of good BOTs include chatbots, search engine bots, and site monitoring BOTs.
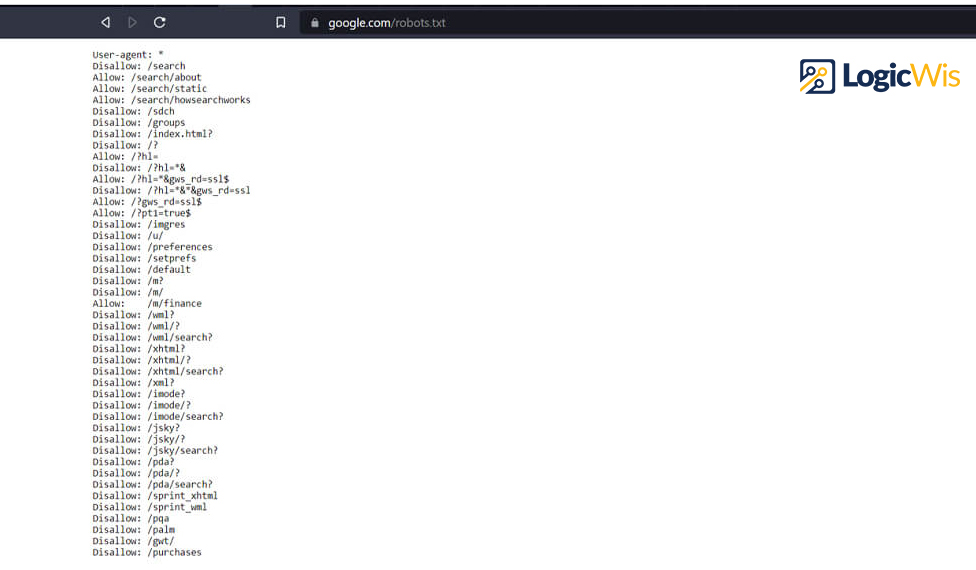
Additionally, good BOTs will follow the limits listed in the robots.txt file, which contains instructions for BOTs visiting the host’s website or application. For instance, a website can provide a rule in the robots.txt file to prevent a specific page from appearing in a Google search, and the Google crawler BOTs will not display that page. However, nasty BOTs regularly disobey the rules in robots.txt because they are not “legal” and cannot be enforced.
In addition to being used to harm target websites and users, “bad BOTs” also include web scrapers and automation bots that are forbidden by owners.
Sadly, not all malevolent BOTs are created with the best of intentions. Bad BOTs can be used for unethical and illegal activities, such as matching brute force attacks and stealing users’ personal information, in the hands of dishonest individuals.
Despite their image as Bad BOTs, web scrapers do not hurt people. As an alternative, they are commonly used for entirely legal functions including automating monotonous operations and obtaining data from the public domain.
Many service providers employ stringent security measures to prevent malicious bots from harming the servers despite the misuse of automation and site scraping BOTs drives.
Due to these protective measures against unethical bots, some excellent BOTs are also prohibited from accessing websites, which increases the difficulty and cost of bot production.
Servers detecting BOTs
The first step in getting over anti-scraping safeguards is understanding how BOT detection works. Service providers use a variety of techniques for identifying BOTs to collect data for statistical models that can recognise bots by observing their non-human behaviour patterns.
IP traffic restriction
BOTs are able to submit several requests utilising a single IP address in a short period of time. Websites can easily detect this strange activity, and if the number of requests reaches a predetermined level, they will either ban the suspect IP address or require the user to complete a CAPTCHA test.
By limiting the amount of network traffic that a single IP address may produce, the bot-mitigation technique known as “IP rate restriction” reduces the stress on web servers and minimises the activity of potentially hazardous bots. This method works particularly well to stop DDoS attacks, brute force attacks, and web scraping.
Investigation of HTTP requests
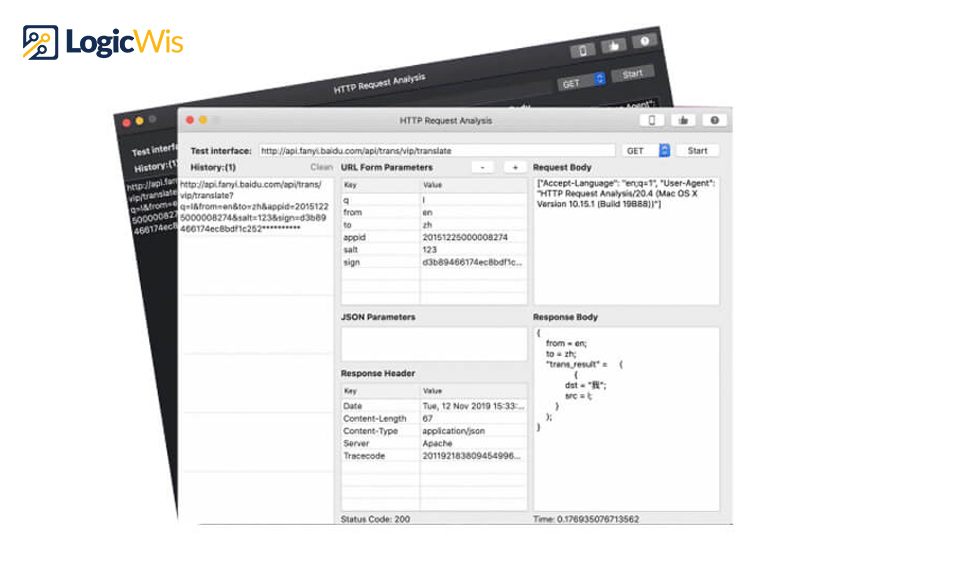
Web browsers use HTTP requests to make the requests for the data they need to load a page.
Each HTTP request from the client to the server includes a set of encoded data that includes details about the client requesting the resource, such as the client’s IP address and HTTP headers.
The information in the HTTP request can be crucial for identifying BOTs because even the order of the HTTP headers can reveal whether the request is coming from a real web browser or a script.
The user-agent header element, which is well-known for detecting BOTs, identifies the client’s browser and its version.
User behaviour analysis
Sentiment analysis does not try to identify BOTs in real time, but instead gathers information about user behaviour over a long period of time to identify certain patterns that become obvious only after sufficient data has been gathered.
It is possible to gather information on the order in which pages are browsed, the length of time spent on a single page, mouse movements, and the speed at which forms are filled out. The IP address of the client can be blacklisted or put through an anti-bot test if there is sufficient evidence that the user isn’t human.
Web browser fingerprinting
The phrase describes the tracking techniques that websites use to compile information about the people that use their servers.
Many websites need the usage of scripts, which can gather in-depth information in the background about the user’s browser, device, operating system, time zone, installed extensions, and other things. Combining these pieces of data yields a fingerprint that can be used to track a client throughout all of their browsing sessions across the internet.
Bots may be recognised by their fingerprints, but to make matters more difficult, websites employ a variety of BOT mitigation strategies. We will also discover the most innovative anti-scraping methods.
Avoiding security precautions
After learning how to spot BOTs on websites and employing anti-scraping techniques to stop BOTs from accessing them.
We can investigate how bots get through these security measures now that we know how websites identify bots and put precautions in place to prevent bots from accessing them.
The browser headers are fake (simulated)
Security precautions against scraping Keep an eye on the HTTP request headers to see if the incoming requests are coming from a reliable browser; if not, the questionable IP address will be blacklisted.
A bot must have a header structure that matches the user agent in order to circumvent this security.
A workaround for the restriction is to launch a browser with a certain user-agent header, as seen in the puppeteer example below.
const browser = puppeteer.launch({
headless: true,
args: [
`–user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36`
]
})